Multimodal
OpenS2V-Eval
180 prompts across 7 categories scoring subject consistency in subject-to-video generation.
Response matrix
Every model, scored item by item.
Each row is an AI model and each column an item, ordered so the strongest models and easiest items gather toward one corner. 19 subjects × 181 items, 68% of cells evaluated.
Fit to width. Hover for subject & item; click a cell for details.
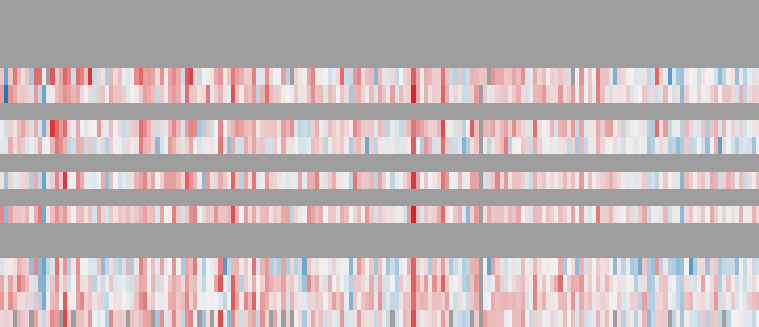
Scale: Per metric, each on its own native scale: subject consistency, face similarity, motion amplitude / smoothness, aesthetics, … for subject-to-video generation; split by prompt domain.
Sample items
What the questions look like — and how subjects answer.
A spread of items across the difficulty range. This benchmark does not publish per-answer traces, so each item shows which subjects succeeded.
Subjects
The models, agents, and reward models evaluated.
19 subjects, ranked by mean response across this benchmark's items.
- 1a4307d612.653
- 2636453042.502
- 3585408182.358
- 494b38d5a2.294
- 50f2ee4e52.256
- 6d0bb3dc52.245
- 79a79f7ea2.221
- 8388a3ad62.204
- 9a9bdfefb2.15
- 10dc92b8a42.149
- 11eaa486772.134
- 127715ffa02.126
- 13198038122.089
- 1451a30f702.082
- 1508a864c12.069
- 165c07c6552.061
- 17efd7debe2.055
- 18e63b58772.043
- 19610cfae31.79