Safety & Security
BenchRisk
Scoring the reliability of LLM benchmarks across 57 failure modes and 196 mitigations.
7items
26subjects
100%observed
Modelsubject type
Response matrix
Every model, scored item by item.
Each row is an AI model and each column an item, ordered so the strongest models and easiest items gather toward one corner. 26 subjects × 7 items, 100% of cells evaluated.
Fit to width. Hover for subject & item; click a cell for details.
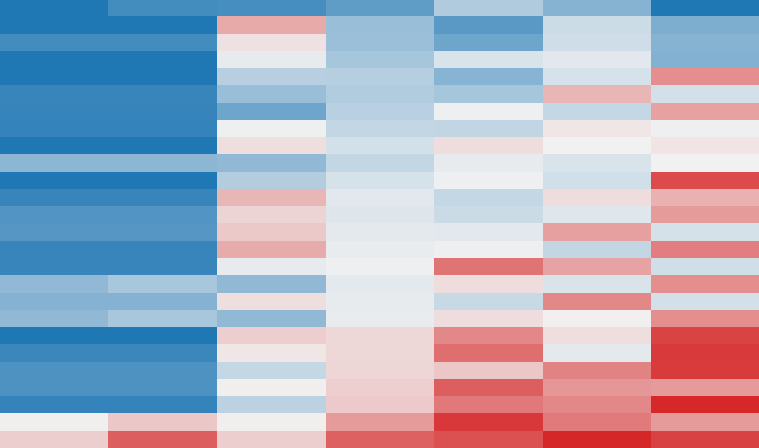
lowhighUnobserved
Scale: 0 to 1 reliability score (higher = a more reliable benchmark).
Sample items
What the questions look like — and how subjects answer.
A spread of items across the difficulty range. This benchmark does not publish per-answer traces, so each item shows which subjects succeeded.
Subjects
The models, agents, and reward models evaluated.
26 subjects, ranked by mean response across this benchmark's items.
- 15b83d9630.706
- 2e0652cf00.593
- 3031cd2060.448
- 41cac18550.447
- 59abf621a0.434
- 66a08f34e0.428
- 7de433ed50.419
- 8ad505a3a0.389
- 9814193e60.383
- 10c4b9e72d0.379
- 11a9dc1b940.372
- 1299665bad0.363
- 1329ad16a30.361
- 1410f901600.353
- 159faa120f0.35
- 1676bf377f0.323
- 17c240e59b0.32
- 18b40a48df0.317
- 1993bc2ca90.296
- 200eb1f54b0.278
- 21bd5a48770.267
- 2212628c870.265
- 23e7b876660.239
- 24a48acf9f0.23
- 2581f48fa30.216
- 262da98da30.115