Reasoning & Knowledge
AbstentionBench
Whether LLMs abstain on unanswerable or underspecified questions across 20 datasets.
Response matrix
Every model, scored item by item.
Each row is an AI model and each column an item, ordered so the strongest models and easiest items gather toward one corner. 23 subjects × 31 items, 88% of cells evaluated.
Fit to width. Hover for subject & item; click a cell for details.
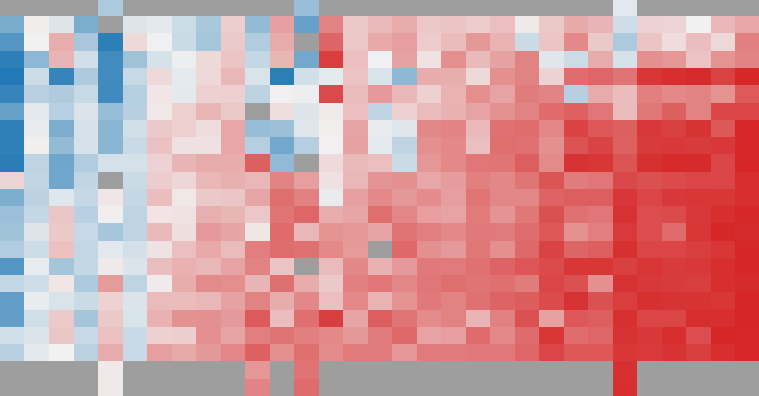
Scale: 0 to 1 (per metric): abstention F1 / precision / recall — how reliably a model declines unanswerable or underspecified questions. The authors release these graded scores, not a per-response binary label.
Sample items
What the questions look like — and how subjects answer.
A spread of items across the difficulty range. This benchmark does not publish per-answer traces, so each item shows which subjects succeeded.
Subjects
The models, agents, and reward models evaluated.
23 subjects, ranked by mean response across this benchmark's items.
- 10dc069200.813
- 2d1f34a950.797
- 3a2a69af70.79
- 4d12230130.779
- 52352da720.779
- 6e7904abf0.771
- 7908fa0fd0.77
- 8dbf1d0c00.767
- 9db68274f0.766
- 1077bd1a280.751
- 1118270ef10.748
- 126c6be7db0.737
- 138aa62b8f0.73
- 1481dd6aa30.725
- 151c7739c10.691
- 1698cfe9c60.691
- 1723e989bc0.666
- 184f87d9ec0.649
- 19cfe3e6380.643
- 20e8b341ee0.633
- 2121f91ce30.616
- 225db1c30d0.596
- 23c1d71a9e0.486